Research Team
Casey Li (UoC)
Luke Parkinson (GRI- UoC)
Xander Cai (GRI – UoC)
Matthew Wilson GRI – UoC)
Pooja Kholsa (GRI – UoC)
Greg Preston (UoC)
Rose Pearson (NIWA)
Rob Deakin (LINZ)
Emily Lane (NIWA)
Cyprien Bosserelle (NIWA)
Funding
FrontierSI and Building Innovation Partnership
Duration
2021-2023
Project summary
The principle aim of the flood resilience digital twin is to improve and facilitate flood risk assessment and emergency management through automation. This entails the automation of data ingestion, processing, and analysis, enabling the rapid evaluation of multiple scenarios with updated information, and ultimately making the assessment more efficient and cost-effective.
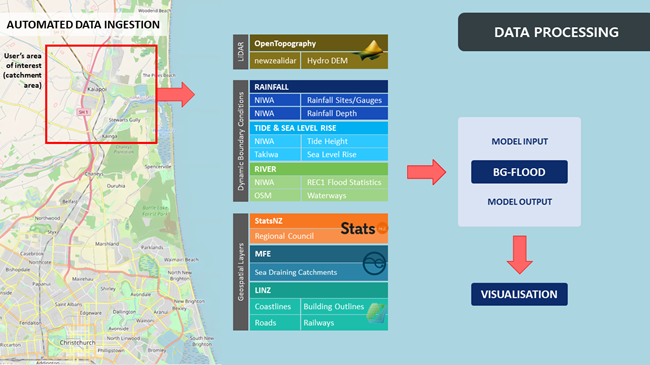
A design principle for the digital twin was that, for a selected area, data not already present in the database would be retrieved from their respective agencies and added to the local database without any modifications. This approach is adopted to circumvent the transmission of multiple repetitive GET requests and expedite data processing. After that, data are further processed within the digital twin to produce standardized model inputs consumable by BG-Flood, which is NIWA’s flood modelling tool. These model inputs are then used to run the BG-Flood model to produce model output, which is subsequently incorporated back into the digital twin for further analysis.
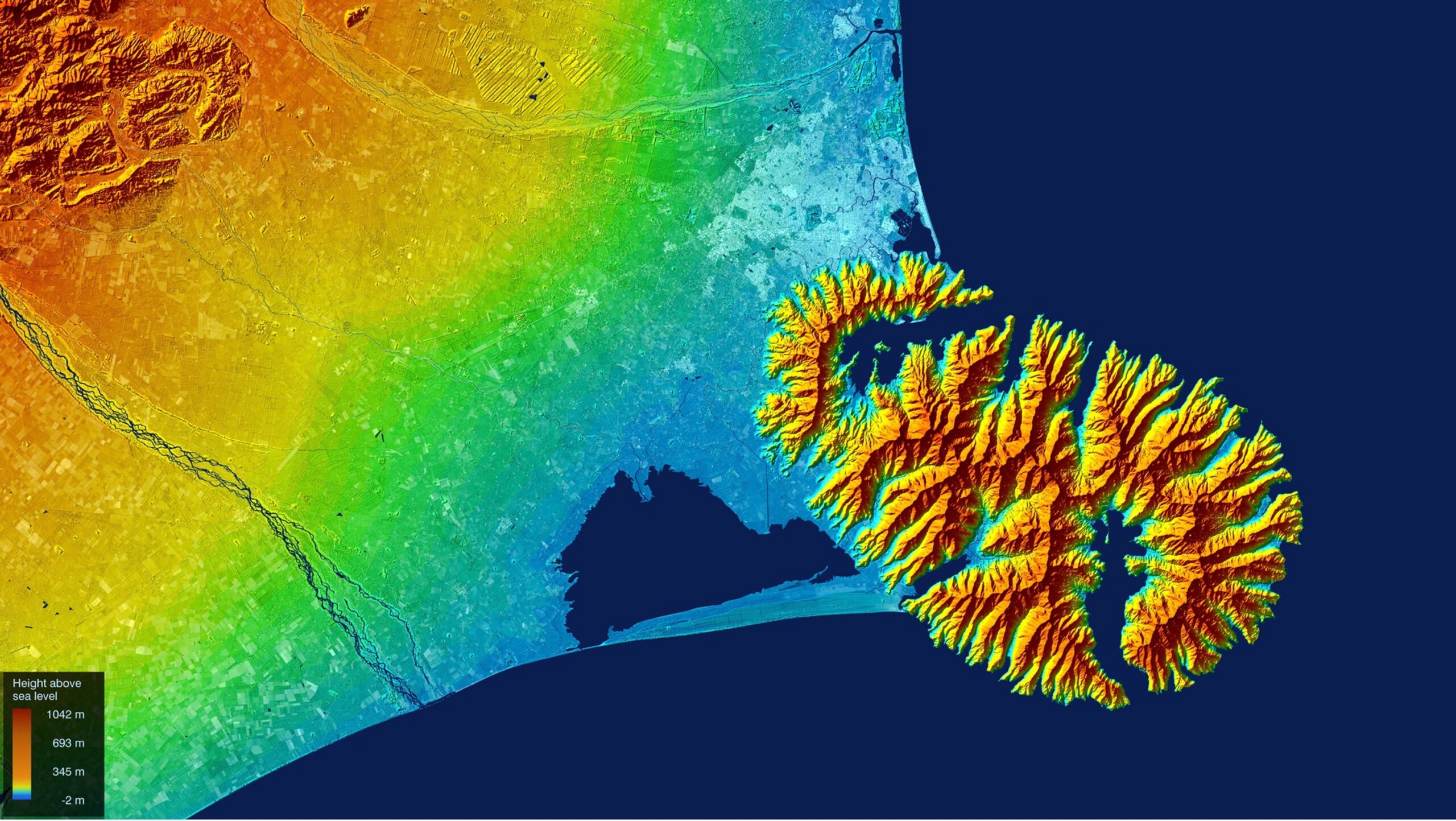
As shown in the figure above, a substantial amount of spatial data is required, sourced from various agencies in diverse formats, and often varying in quality. A key input for a flood model is high-resolution topography. The digital twin will acquire LiDAR point cloud data for the area of interest (AOI) from OpenTopography, then automatically process this data to generate a hydrologically conditioned digital elevation model for use in the BG-Flood model.
For rainfall, depth-duration-frequency statistics for rain gauges across the country under different climate change scenarios, obtained from NIWA’s High Intensity Rainfall Design System, are used. The digital twin uses the Thiessen polygon method to determine the coverage area of each gauge. When a user selects an AOI, its extent is intersected with these polygons, and the necessary data for each gauge within the AOI for the requested scenario is retrieved from HIRDS. A hyetograph is created for each of these gauges and combined to produce the rainfall model input for BG-Flood.
For tide, if the AOI is within 1km of the coastline, the annual king tide for the year is obtained from NIWA’s Tide Forecaster for the nearest available location. Since this data lacks sea level observations, the digital twin subsequently retrieves sea level rise data from Takiwa’s NZSeaRise project. This enables the incorporation of varying sea levels on top of the tide level, addressing a key limitation.
For river flow, data from NIWA’s River Environment Classification (REC), version 1 is used. This dataset provides flood level estimates for different annual exceedance probabilities, for river vector data across the country. However, their locations often do not precisely align with the rivers in the LiDAR data. To improve accuracy, the river vectors that serve as inflows into the AOI are aligned with waterway data obtained from OpenStreetMap, then the LiDAR elevation data are used to search the local neighbourhood for the correct location of the river entry point into the AOI. After that, hydrographs are generated for river inflow vectors into the AOI, creating the necessary inputs for BG-Flood.
Finally, after running the BG-Flood model, the model output, in conjunction with infrastructure data like building outlines, are used to determine the buildings that are flooded, the depth of the flooding, and obtain statistics on this.